写在前面
kubectl虽然查询单个的kubernetes资源或者列表都已经比较方便,但是进行更为多个资源的联合查询(比如pod和node),以及查询结果的二次处理方面却是kubectl无法胜任的。所以一直以来,我都有想法将kubernetes作为数据库进行查询。在去年,我开发了第二个版本的kubesql。相关信息在https://xuxinkun.github.io/2019/03/11/kubesql/,代码留存在https://github.com/xuxinkun/kubesql/tree/python。这个版本较之我最早的spark离线方式已经有所改观,但是无法应对中型、甚至较小规模的集群,性能上存在较大问题。部署上也较为繁杂,且不够稳定,有一些bug(会异常退出)。而且对于label等字段都无法处理,可用性较差。我总起来不满意,但是一直没时间去重构。直到最近,听了关于presto的一个分享,我感觉重构的机会来了。
这一次kubesql完全抛弃了原有的架构,基于presto进行开发。这里摘抄一段presto的简介:presto是一个开源的分布式SQL查询引擎,适用于交互式分析查询,数据量支持GB到PB字节。Presto的设计和编写完全是为了解决像Facebook这样规模的商业数据仓库的交互式分析和处理速度的问题。presto具有丰富的插件接口,可以极为便捷的对接外部存储系统。
考虑使用presto的主要原因是避免了SQL查询引擎的逻辑耦合到kubesql中,同时其稳定和高性能保证了查询的效率。这样kubesql的主要逻辑专注于获取k8s的resource变化,以及将resource转化为关系型数据的逻辑上。
kubesql使用
先介绍下如何部署和使用。部署方式目前主要使用docker部署,很快会支持k8s的部署方式。
部署前需要获取kubeconfig。假设kubeconfig位于/root/.kube/config路径下,则只要一条命令即可运行。
docker run -it -d --name kubesql -v /root/.kube/config:/home/presto/config xuxinkun/kubesql:latest
如果桥接网络不能通k8s api,则可以使用物理机网络,加入–net=host参数即可。注意presto端口使用8080,可能会有端口冲突。
而后就可以进行使用了。使用命令为
docker exec -it kubesql presto --server localhost:8080 --catalog kubesql --schema kubesql
这时自动进入交互式查询模式,即可进行使用了。目前已经支持了pods和nodes两种资源的查询,对应为三张表,nodes,pods和containers(container是从pod中拆出来的,具体原因见下文原理一节)。
三张表支持的列参见https://github.com/xuxinkun/kubesql/blob/master/docs/table.md。
presto支持一些内置的函数,可以用这些函数来丰富查询。https://prestodb.io/docs/current/functions.html。
这里我举一些使用kubesql查询的例子。
比如想要查询每个pod的cpu资源情况(requests和limits)。
presto:kubesql> select pods.namespace,pods.name,sum("requests.cpu") as "requests.cpu" ,sum("limits.cpu") as "limits.cpu" from pods,containers where pods.uid = containers.uid group by pods.namespace,pods.name
namespace | name | requests.cpu | limits.cpu
-------------------+--------------------------------------+--------------+------------
rongqi-test-01 | rongqi-test-01-202005151652391759 | 0.8 | 8.0
ljq-nopassword-18 | ljq-nopassword-18-202005211645264618 | 0.1 | 1.0
又比如我想要查询每个node上剩余可以分配的cpu情况(用node上allocatable.cpu减去node上所有pod的requests.cpu的总和)
presto:kubesql> select nodes.name, nodes."allocatable.cpu" - podnodecpu."requests.cpu" from nodes, (select pods.nodename,sum("requests.cpu") as "requests.cpu" from pods,containers where pods.uid = containers.uid group by pods.nodename) as podnodecpu where nodes.name = podnodecpu.nodename;
name | _col1
-------------+--------------------
10.11.12.29 | 50.918000000000006
10.11.12.30 | 58.788
10.11.12.32 | 57.303000000000004
10.11.12.34 | 33.33799999999999
10.11.12.33 | 43.022999999999996
再比如需要查询所有所有2020-05-12后创建的pod。
presto:kube> select name, namespace,creationTimestamp from pods where creationTimestamp > date('2020-05-12') order by creationTimestamp desc;
name | namespace | creationTimestamp
------------------------------------------------------+-------------------------+-------------------------
kube-api-webhook-controller-manager-7fd78ddd75-sf5j6 | kube-api-webhook-system | 2020-05-13 07:56:27.000
还可以根据标签来查询,查询所有标签的appid是springboot,且尚未调度成功的pod。以及计数。
标签appid在pods表里则会有一列,列名为”labels.appid”,使用该列作为条件来删选pod。
presto:kubesql> select namespace,name,phase from pods where phase = 'Pending' and "labels.appid" = 'springboot';
namespace | name | phase
--------------------+--------------+---------
springboot-test-rd | v6ynsy3f73jn | Pending
springboot-test-rd | mu4zktenmttp | Pending
springboot-test-rd | n0yvpxxyvk4u | Pending
springboot-test-rd | dd2mh6ovkjll | Pending
springboot-test-rd | hd7b0ffuqrjo | Pending
presto:kubesql> select count(*) from pods where phase = 'Pending' and "labels.appid" = 'springboot';
_col0
-------
5
kubesql原理
kubesql的架构如图所示:
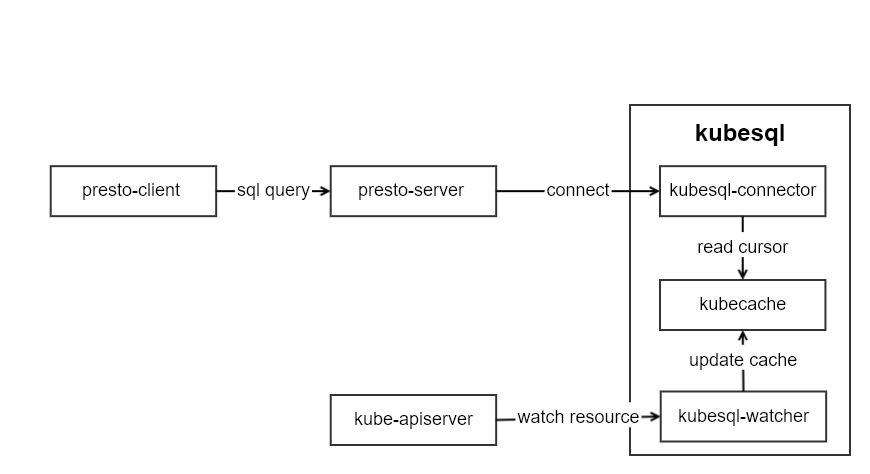
kubesql里主要有三个模块部分:
- kubesql-watcher: 监听k8s api pod和node的变化。并将pod和node的结构化数据转化为关系型数据(以Map的方式进行保存)。
- kubecache: 用于缓存pod和node的数据。
- kubesql-connector: 作为presto的connector,接受来自presto的调用,通过kubecache查询列信息和对应数据,并返回给presto关于列和数据的信息。
其中最主要的部分是kubesql-connector。presto插件开发指南可以参考https://prestodb.io/docs/current/develop.html。我没有选择从零开始,而是基于已有的localfile插件https://github.com/prestodb/presto/tree/0.234.2/presto-local-file进行的开发。如何进行presto的插件开发,后面我再写文章来解读。
由于所有数据都缓存在内存中,因此几乎无磁盘需求。但是也需要根据集群的规模来提供较大的内存。
以pod数据为例,pod中主要数据分成三部分,metadata,spec和status。
metadata中比较难以处理的部分是label和annotation。我将label这个map进行展平,每个key都作为一列。比如
labels:
app: mysql
owner: xxx
我使用labels作为前缀,拼合labels里面的key作为列名。从而得到两条数据为:
labels.app: mysql
labels.owner: xxx
对于pod A存在app的label但是pod B并没有该标签,则对于pod B来说,该列labels.app的值则为null。
类似的annotations也是类似的处理方式。从而让annotations也就可以成为可以用于筛选pod的条件了。
对于spec来说,最大的困难在于containers的处理。因为一个pod里面可能有若干个containers,因此我直接将containers作为一张新的表。同时在containers表里增加一个uid的列,用来表明该行数据来自于哪个pod。containers里面的字段也对应都加入到containers表中。containers中比较重要的关于资源的如request和limit,我直接使用requests.作为前缀,拼合resource作为列名。比如requests.cpu,requests.memory等。这里cpu的单独处理为double类型,单位为核,比如100m这里会转化为0.1。内存等则为bigint,单位为B。
对于status中,比较难于处理的是conditions和containerStatus。conditions是一个列表,但是每个condition的type不相同。因此我将type作为前缀,用来生成conditon的列名。比如:
conditions:
- lastProbeTime: null
lastTransitionTime: 2020-04-22T09:03:10Z
status: "True"
type: Ready
- lastProbeTime: null
lastTransitionTime: 2020-04-22T09:03:10Z
status: "True"
type: ContainersReady
那么在pod表中,我对应可以得到这些列:
| Column | Type | Extra | Comment |
|---|---|---|---|
| containersready.lastprobetime | timestamp | ||
| containersready.lasttransitiontime | timestamp | ||
| containersready.message | varchar | ||
| containersready.reason | varchar | ||
| containersready.status | varchar | ||
| ready.lastprobetime | timestamp | ||
| ready.lasttransitiontime | timestamp | ||
| ready.message | varchar | ||
| ready.reason | varchar | ||
| ready.status | varchar |
这样我就可以通过”ready.status” = “True” 来筛选condition里type为ready且status为True的pod了。
containerStatus因为与containers一一对应,因此我将containerStatus合并到containers表里,并且根据container name一一对应起来。
后记
本次重构后kubesql我直接发布为1.0.0版本,并且已经在日常使用了。且借助于内存和presto的高性能,我测试过5万pod的集群,查询时间为毫秒级。目前暂未发现明显的bug。大家有发现bug或者新的feature也可以提issue给我。我后期也会再维护该项目。
因为目前只有pods和nodes资源,相对于k8s庞大的资源来说,还只是冰山一角。但是增加每个资源要加入相当数量的代码。我也在考虑如何使用openapi的swagger描述来自动生成代码。
部署上现在是用docker来部署,马上也会增加kubernetes的部署方式,这样会更加便捷。
同时我在考虑,在未来,让presto的每个worker负责一个集群的cache。这样一个presto集群可以查询所有的k8s集群的信息。该功能还需要再做设计和考虑。
出处:xinkun的博客
链接:https://xuxinkun.github.io/
本文版权归作者所有,欢迎转载。
未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
欢迎扫描右侧二维码关注微信公众号xinkun的博客进行订阅。也可以通过微信公众号留言同作者进行交流。