kube-liveboard
随着kubernetes 集群的增大,对于集群数据选取恰当的形式进行展示有助于直观反映集群的状态,方便发现集群的短板,了解集群的瓶颈。因此,笔者做了kube-liveboard这个项目用以实现以上目标,实现集群状态的可视化。
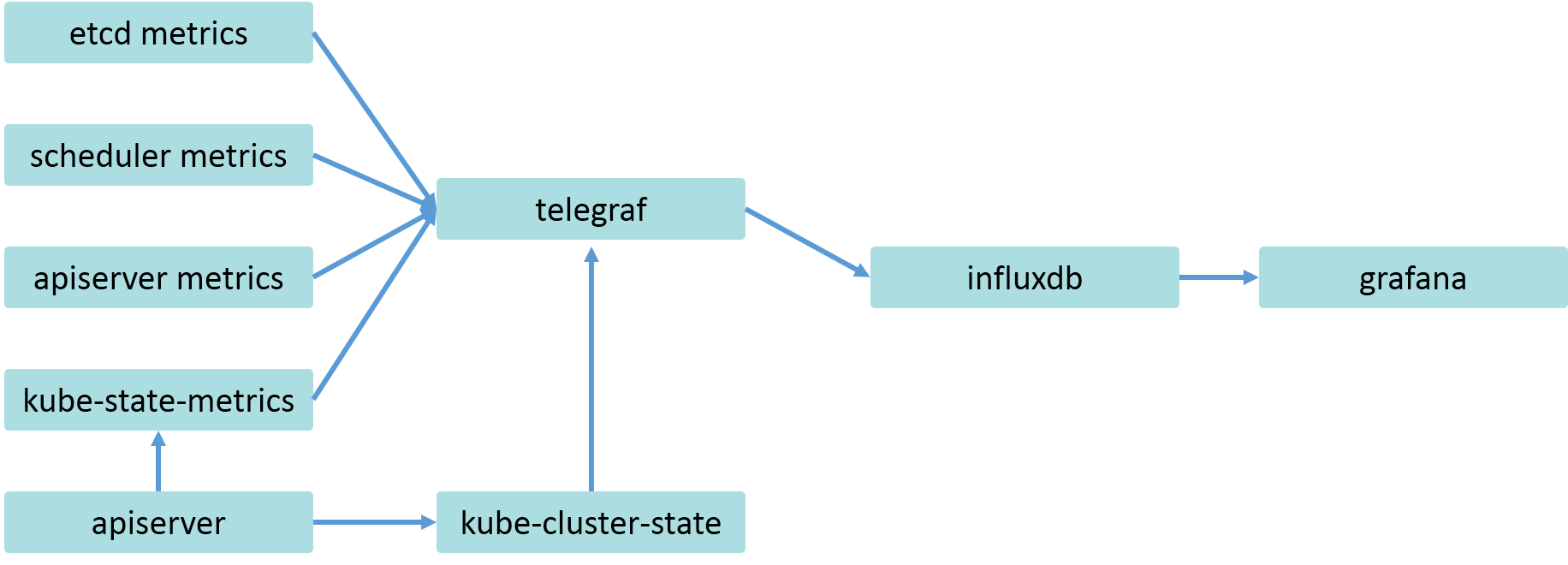
从apiserver中可以获取所有的资源信息,社区目前有kube-state-metrics项目对各项资源进行分别的统计,并形成metrics接口。笔者自己也开发了一个类似的项目,kube-cluster-state,用以统计比如每个node上容器个数、request资源分配率、limit资源分配率、集群中容器各之类的指标。
除了以上这两个数据源,笔者还整合了master组件中如scheduler、etcd、apiserver等组件的metrics接口。通过telegraf将metrics接口的数据推送到influxdb中。并最终通过grafana进行展示。
不同的指标需要通过不同的形式进行展示。许多的原始数据需要进行整合、丰富和二次加工,以便在展示时更加直观。本文介绍一下在kube-liveboard中一些典型指标的处理方式以及展现形式。
比如apiserver的metrics接口可以提供各种资源的请求次数、延时的统计,笔者可以将其进行计算,得到apiserver的请求速率。同样,通过调度的次数和调度时长的统计,也可以得到调度的吞吐率。
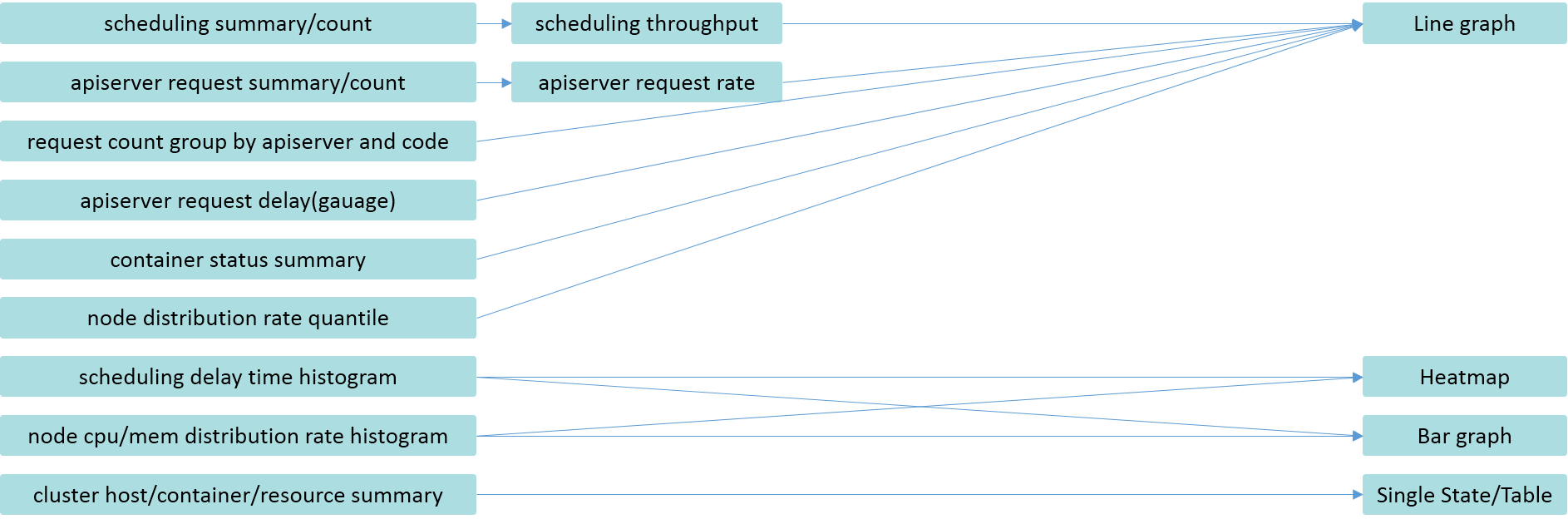
apiserver的请求延时、请求速率、请求计数、容器状态等,这些指标笔者更关心其随时间的变化,以便对比了解其变化情况,因此采用折线图的方式进行展示。
调度的延时、node节点上cpu和内存的分配率的直方图统计,则可以使用柱状图和热力图进行展示。对于集群的物理机、容器、各项资源的总和情况,因为笔者更为关注其现在的状态,因此一般采用SingleState或者表格的形式进行展示。
本文将对以上指标的展示界面进行介绍。这里使用的是笔者的一个仿真集群的数据。
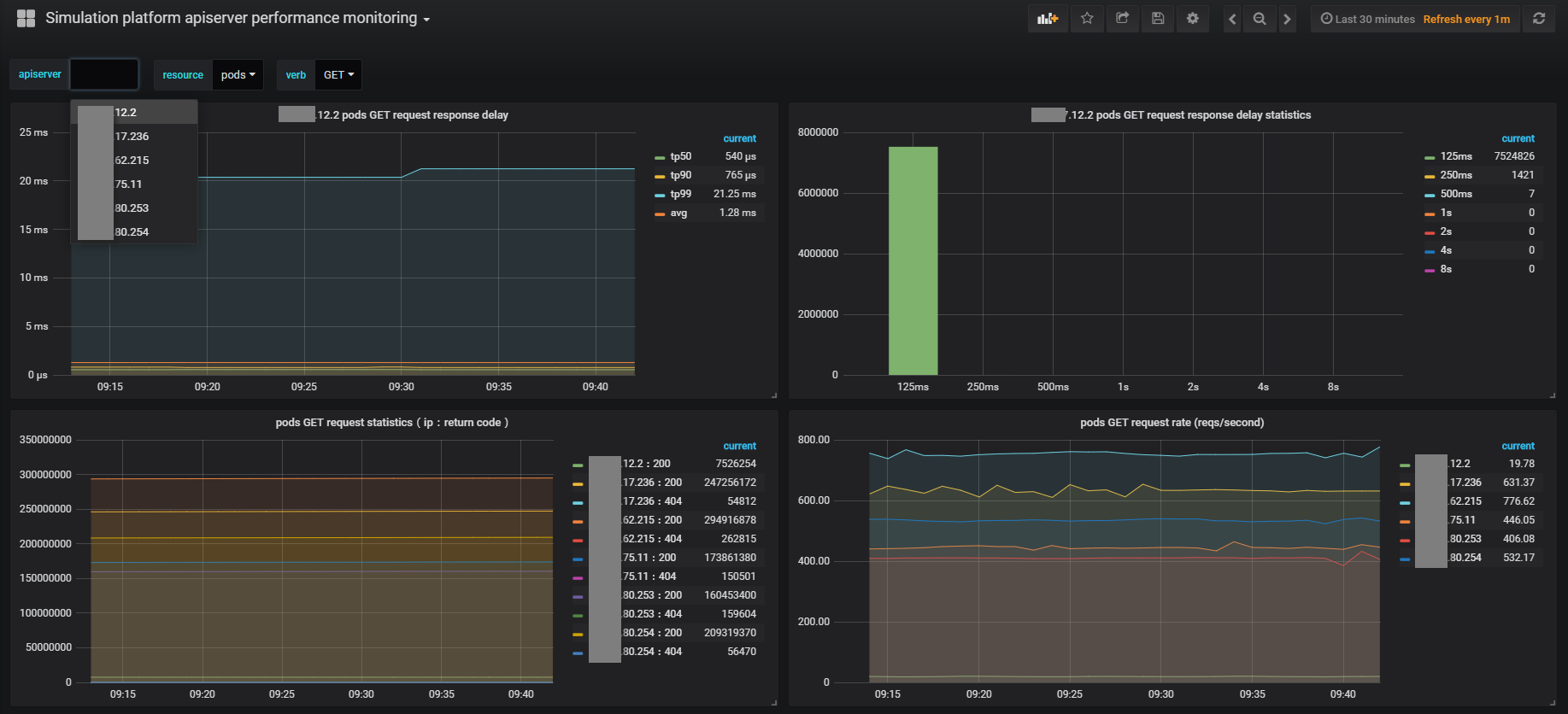
下图主要展示的是单个apiserver的性能监控。这里可以切换不同的apiserver和不同的资源以及不同的请求方式,展示其请求的速率,不同返回值的计数,请求的tp50/tp90/tp99/均值延时的情况以及请求延时的直方图统计情况。
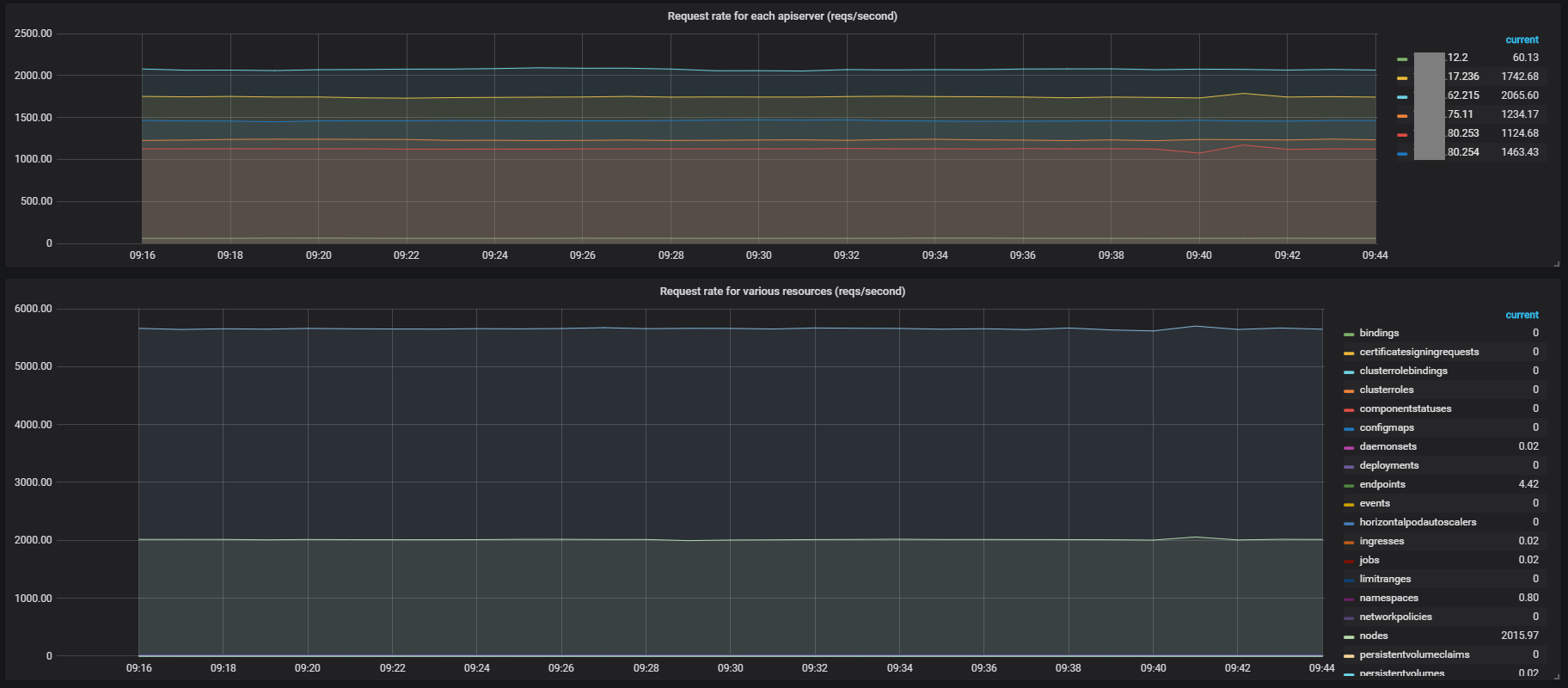
下图主要展示的是汇总的apiserver的性能监控。这里可以查看不同的apiserver的请求速率。总的apiserver不同资源的请求速率。通过这些指标可以了解目前apiserver的负载是否均衡,哪种资源请求的速率最多,以便在apiserver出现性能瓶颈时进行分析。
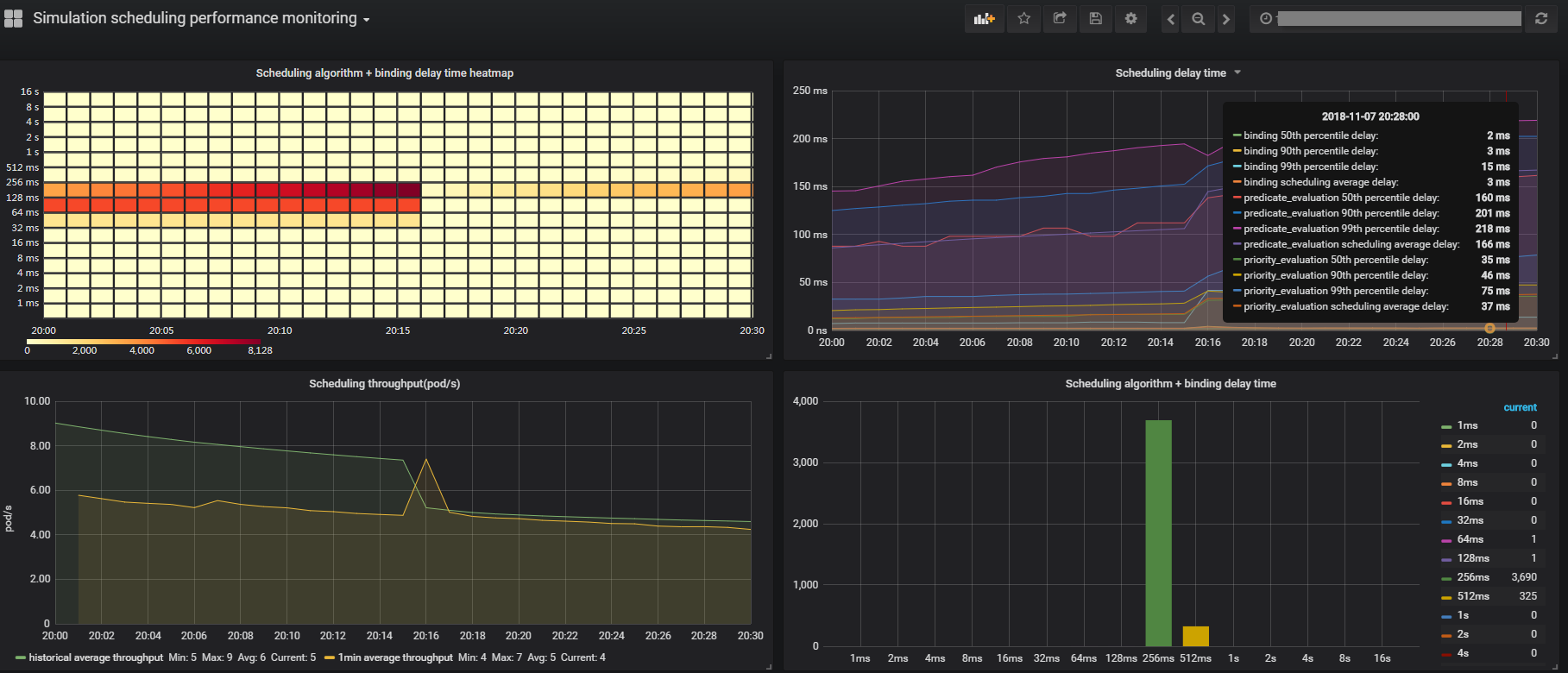
下图主要是调度性能的监控。展示了调度延时的热力图变化,调度的各个阶段延时统计情况,调度的吞吐量以及调度延时的直方图统计。通过这些图表,可以了解调度器目前的性能情况,以及调度各个阶段的情况。
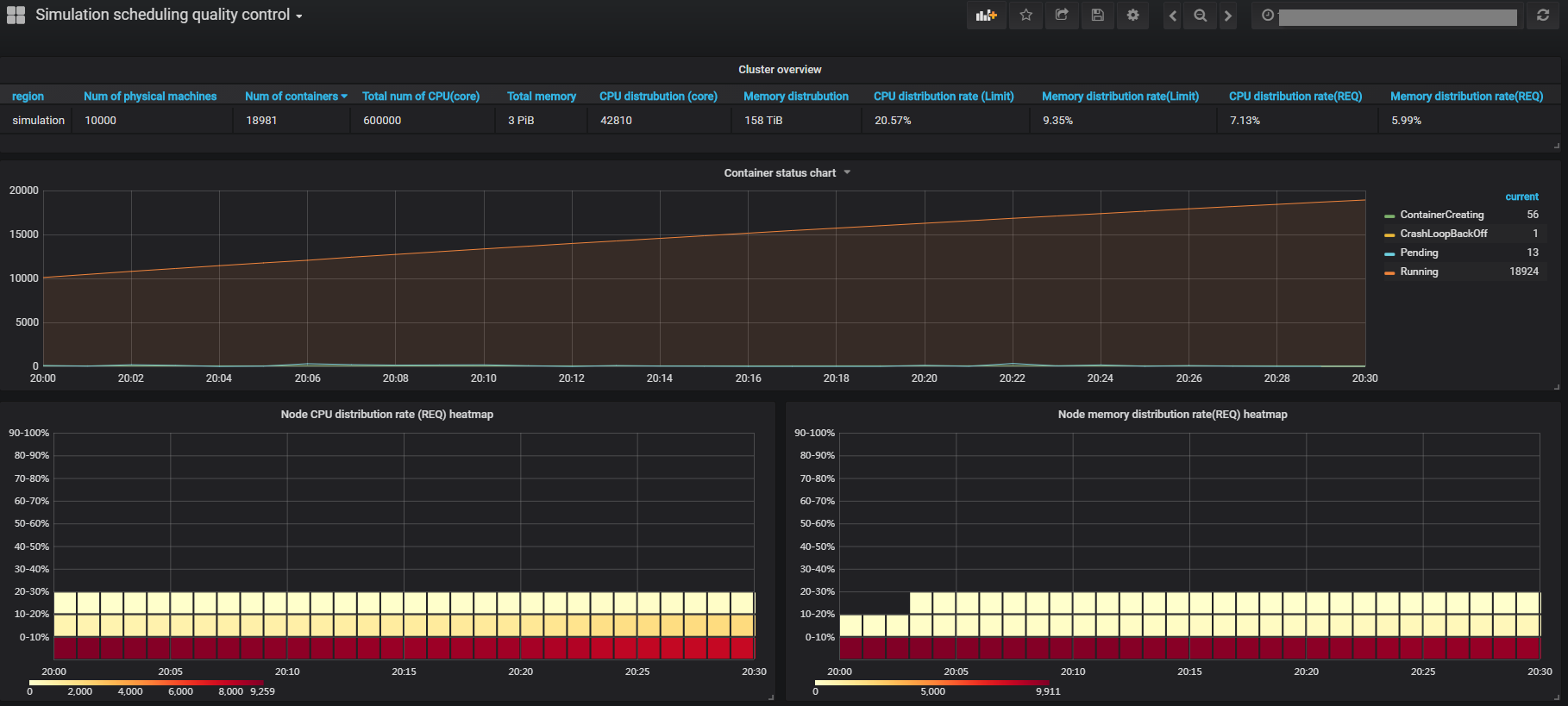
下图主要是整个集群的状态,主要展示了集群资源信息总览,各个状态的容器统计以及节点资源分配率的热力图。从这些图表中可以了解整个集群的状态变化。
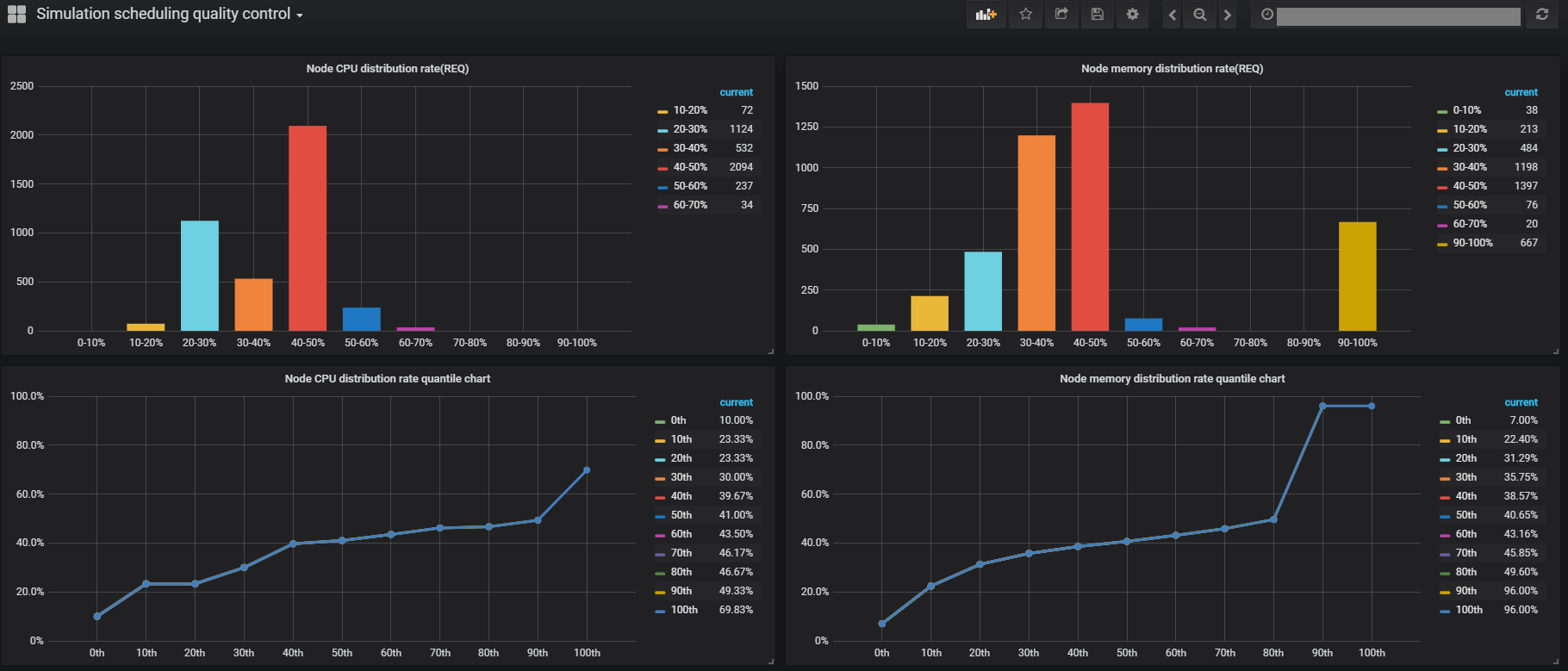
下图是调度质量监控,主要展示了当前的调度分配率直方图和分位图。从中可以反应出调度是否均衡,以及整个集群的资源瓶颈等。
出处:xinkun的博客
链接:https://xuxinkun.github.io/
本文版权归作者所有,欢迎转载。
未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
欢迎扫描右侧二维码关注微信公众号xinkun的博客进行订阅。也可以通过微信公众号留言同作者进行交流。